What is Big Data and Hadoop

The information which are very large in size is called Big Data.
Typically we chip away at the information of size MB(WordDoc, Excel) or most
extreme GB(Movies, Codes) however the information in Petabytes for example 10^15
byte size is called Big Data. It is expressed that practically 90% of the
present information has been produced in the previous 3 years.
Wellsprings of Big Data
This information originated from numerous sources like
Social
networking sites:
Facebook, Google, LinkedIn every one of these destinations creates tremendous the measure of information on an everyday premise as they have billions of clients
around the world.
E-commerce
site: Sites
like Amazon, Flipkart, Alibaba creates an immense measure of logs from which
clients purchasing patterns can be followed.
Climate Station: All the climate station and
satellite gives very enormous information which is put away and controlled to
estimate climate.
Telecom organization: Telecom mammoths like Airtel,
Vodafone study the client patterns and as needs be distributed their
arrangements and for this, they store the information of its million clients.
Share
Market: Stock
trade over the world creates an immense measure of information through its day by
day exchange.
3V's of Big Data
Speed: The information is expanding at a
very quick rate. It is assessed that the volume of information will twofold in
every 2 years.
Assortment: Nowadays information is not put
away in lines and section. Information is organized just as unstructured. Log
record, CCTV film is unstructured information. The information which can be spared
in tables is organized information like the exchange information of the bank.
Volume: The measure of information which we
manage is of very large size of Petabytes.
Hadoop is an open-source system from Apache and is utilized
to store process and investigate information which is colossal in volume. Hadoop is written in Java and isn't OLAP (online logical preparing). It is
utilized for group/disconnected processing. It is being utilized by Facebook,
Yahoo, Google, Twitter, LinkedIn and some more. Additionally, it very well may
be scaled up just by including hubs in the group.
Modules of Hadoop
HDFS: Hadoop Distributed File System.
Google distributed its paper GFS and based on that HDFS was created. It
expresses that the documents will be broken into squares and put away in hubs
over the conveyed design.
Yarn: Yet another Resource Negotiator is
utilized for work booking and deal with the bunch.
Guide Reduce: This is a structure which
encourages Java projects to do the equal calculation on information utilizing
key worth pair. The Map task takes input information and changes over it into
an informational collection which can be processed in Key worth pair. The yield
of Map task is devoured by decrease errand and afterwards the out of reducer
gives the ideal outcome.
Hadoop Common: These Java libraries are utilized
to begin Hadoop and are utilized by other Hadoop modules.
The Hadoop design is a bundle of the document framework,
MapReduce motor and the HDFS (Hadoop Distributed File System). The MapReduce
motor can be MapReduce/MR1 or YARN/MR2.
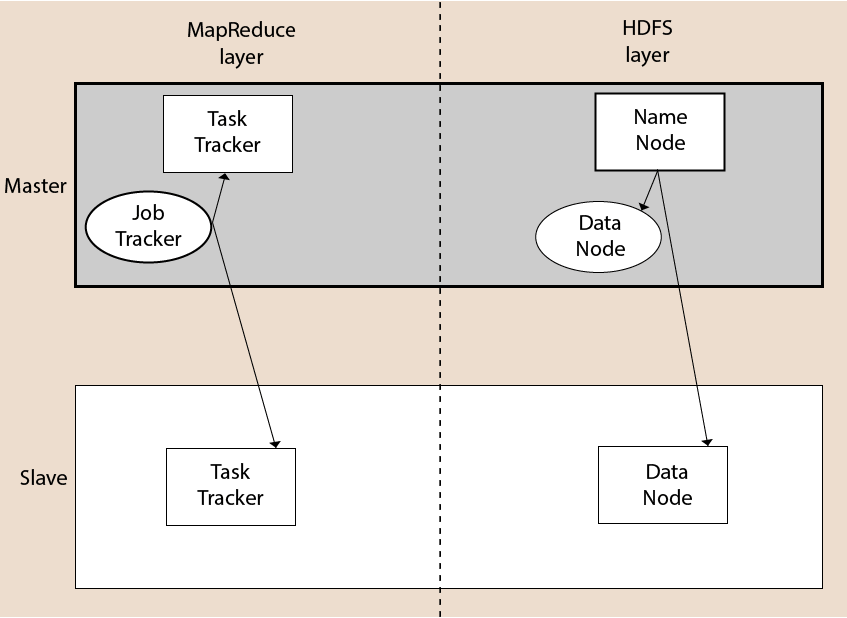
A Hadoop group comprises of a solitary ace and various slave
hubs. The ace hub incorporates Job Tracker, Task Tracker, NameNode, and
DataNode while the slave hub incorporates DataNode and TaskTracker.


Comments
Post a Comment